Image Segmentation
Lecture 1
Introduction
Image Segmentation is the process of partitioning an image into multiple meaningful segments/regions.
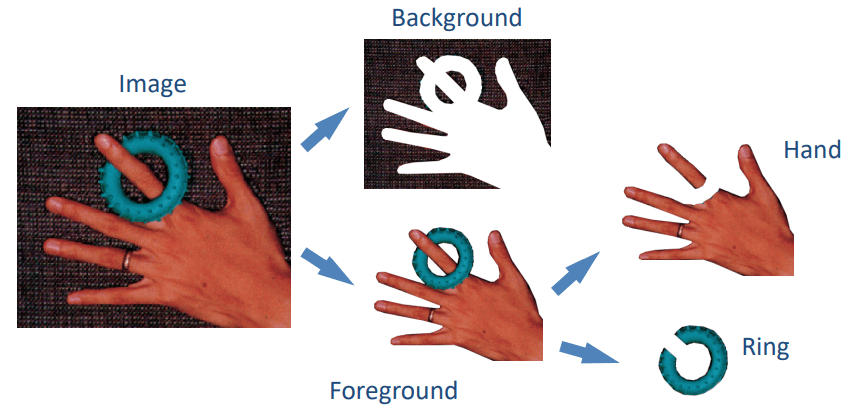
From the above image, we can see that the image is divided into multiple segments. Each segment represents a different object in the image. But how do we define these regions? We need some basic properties:
-
Homogeneity: Pixels in the same region should have similar properties (uniformity).
-
Difference: Adjacent regions should have significantly different values in terms of the characteristics in which individually they are uniform.
-
Simple: Region interiors should be simple and without holes or missing parts
-
Smoothness: Boundaries should be smooth and continuous.
-
Accuracy: Boundaries should be accurate and not too jagged.
Levels of region identification and segmentation
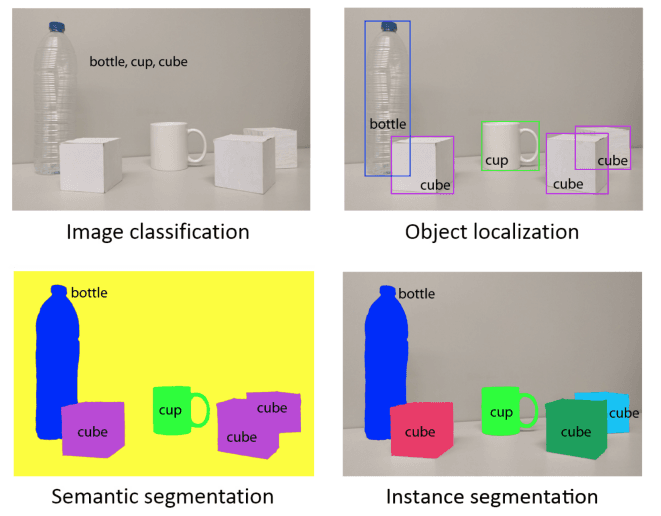
From the image, we can see that there are different levels of region identification and segmentation. The levels are:
-
Image classification vs object localization: Image classification is the process of classifying the entire image into a single category. Object localization is the process of identifying the location of an object in an image.
-
Semantic segmentation vs instance segmentation: Semantic segmentation is the process of classifying each pixel in an image into a category. Instance segmentation is the process of identifying each object in an image and classifying each pixel in the object into a category.
From the example above, we can see that on the semantic level, the cubes are classified as one category, but on the instance level, each cube is classified as a different instances (as shown in different colours).
Methods for segmentation
There are different methods for segmentation. Some of the methods are:
- Region based
- Contour based
- Template matching based
- Splitting and merging based
- Global optimisation based
Basic Segmentation Methods
Thresholding
Thresholding is the simplest method of image segmentation. It is used to separate an image into two parts. The pixels with intensity values above a certain threshold are assigned to one region, and the pixels with intensity values below the threshold are assigned to another region. It can be used when the background and foreground are clearly separated.
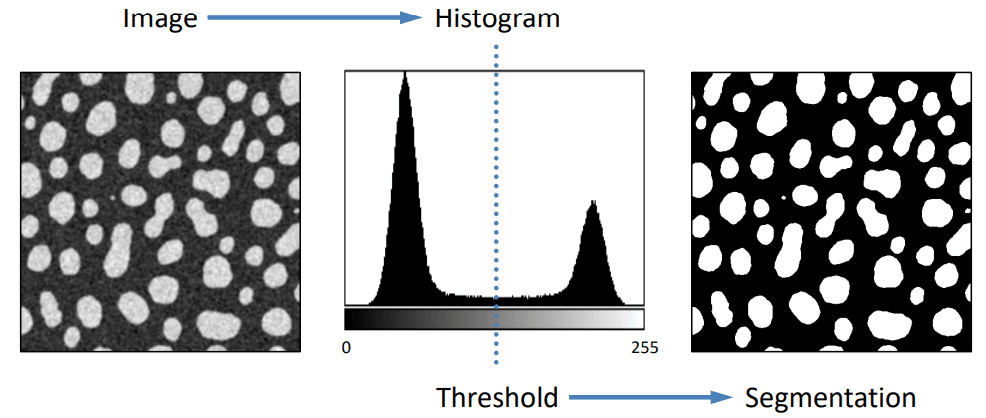
However, as you can imagine, this approach has issues when regions have overlapping intensity distribution. For example, if these cells have overlapping intensity distribution, thresholding will not be able to separate them. The result will have a lot of noise (false positives/false negatives).
K-Means Clustering
K-means clustering is a simple unsupervised learning algorithm that is used to partition an image into K clusters. The algorithm works by iteratively assigning each pixel to the nearest cluster centroid and then recalculating the centroid of each cluster. The process is repeated until the centroids converge. K-means clustering can only be used when the number of clusters is known. The algorithm is sensitive to the initialisation of the centroids.
Feature Based Segmentation
Feature-based segmentation is a method that uses the features of an image to segment it. The features can be colour, texture, shape, etc. The features are used to group similar pixels together. The features can be used to define the regions of interest. For example, in the image below, the features can be used to segment the image into different regions. However, the features need to be carefully selected to ensure that the regions are accurately segmented.
Sophisticated Segmentation Methods
Region Splitting and Merging
- Recursive split the whole image into pieces based on region statistics
- Recursively merge regions together in a hierarchical fashion
- Combine splitting and merging sequentially
The extreme case is going down all the way to the pixel level. The algorithm is as follows:
-
Splitting: Start with the whole image as a single region. Split the region into smaller regions based on some criteria (e.g. variance, mean, etc.). The splitting can be done in different ways (e.g. quadtree, octree, etc.).
-
Merging: Merge the regions together based on some criteria (e.g. variance, mean, etc.). The merging can be done in different ways (e.g. quadtree, octree, etc.).
-
Stopping Criteria: Stop the process when the regions are homogeneous enough.
Connected Components
- 2D image: 4-connected or 8-connected
- 3D image: 6-connected 18-connected or 26-connected
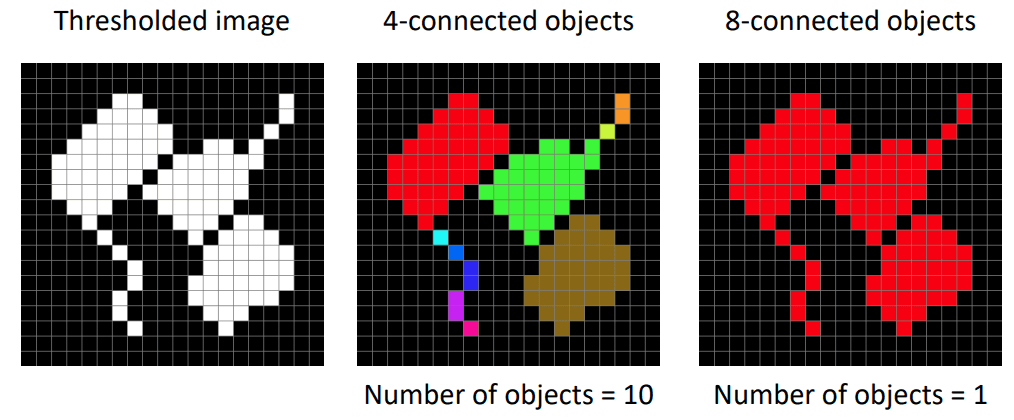
connected components algorithm
-
First pass:
- Check each pixel
- If an object pixel, check its neighbours ( or )
- If no neighbours have labels, assign a new label
- If neighbours have labels, assign the smallest label
- Record label equivalences while assigning Equivalence sets {1, 2, 6} {3, 4, 5}
-
Second pass
- Check each pixel(top left to bottom right)
- Replace the label with the smallest label in the equivalence set
- All background pixels are labelled 0
Heuristic based region merging
- using the relative boundary lengths and edge strengths
- using the relative boundary closest points or farthest points
- use the average colour difference or size difference
Graph-based region merging
- use relative dissimilarities between regions R to merge
- Represent regions as a graph using minimum spanning tree (MST)
- Define a dissimilarity measure w such as intensity difference, colour difference, texture difference, etc.
- Compute internal region dissimilarity using the graph edges e
- Compute the dissimilarity between regions and
Watershed Segmentation
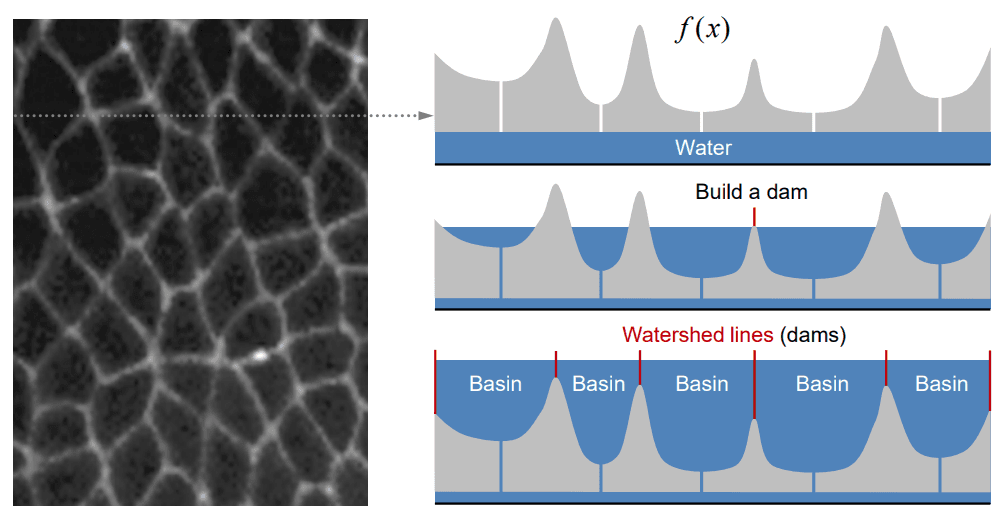
Meyer's flooding algorithm
- Choose a set of markers to start the flooding. These could be, for example, all local minima. Give each a different label.
- Put neighbouring pixels of each marker into a priority queue. A pixel with more similar gray value has higher priority.
- Pop the pixel with the highest priority level from the queue. If the neighbours of the popped pixel that have already been labelled all have the same label, then give the pixel that same label. Put all non-labelled neighbours that have never been in the queue into the queue.
- Repeat step 3 until the queue is empty
Issues with Watershed Segmentation: you may have several local minima in the image, which will result in over-segmentation. To avoid this, you can smooth the image before applying the watershed algorithm.
The other thing is that the watershed algorithm only works with dark background and bright objects. If you have a bright background and dark objects, you can invert the image before applying the watershed algorithm.
Maximally stable extremal regions (MSER)
Basics of maximally stable extremal regions (MSER)
- Connected components characterised by almost uniform intensity surrounded by contrasting background
- Constructed through a process of trying multiple thresholds and analyzing the shape of the connected components
- Selected regions are connected components whose shape remains virtually unchanged over a large set of thresholds.
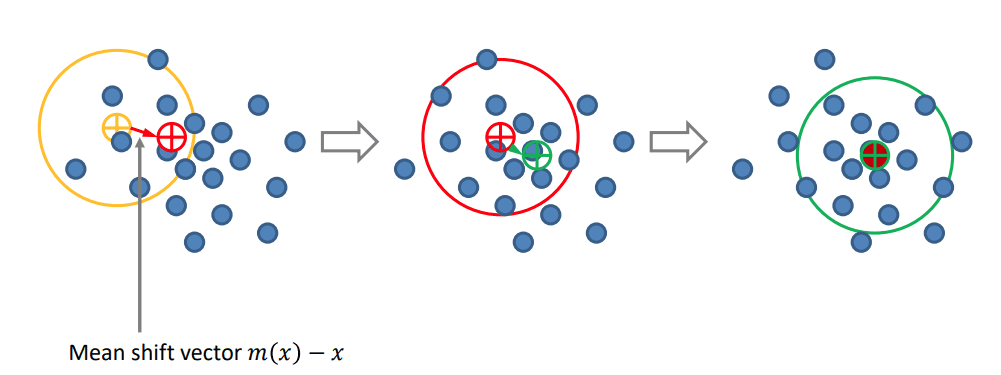
Mean-shifting algorithm
- Initialize a random seed point 𝑥 and window 𝑁
- Calculate the mean (center of gravity) 𝑚(𝑥) within 𝑁
- Shift the search window to the mean
- Repeat Step 2 until convergence